MSF Revamp
It’s an exciting time for SARD at the moment, heading into summer with new recruits left, right and centre, our fundraising target hitting the 10% mark, and lots of big projects underway! One of those projects is my personal favourite: Multi-Source Feedback (MSF).
The Plan
Our MSF module is small and simple on the surface, making it one of the easier parts of SARD to run. We get feedback regularly from doctors and admins alike, but we are not a large development team and have to prioritise the requests and new features, based on necessity/greatest reach. We often get asked about our benchmarking data and whether improvements can be made to the MSF report. Another common request is the ability to use different patient feedback forms, e.g. from the Royal College of Anaesthetists.
So benchmarking, the report, and feedback forms became the epic features of the project, with lots of little improvements being made here and there.
The Progress
For the past 10 months benchmarking has been one of the forefronts of my work, but let’s break it down a bit:
Benchmarking data is used to enable medics to compare themselves among other industry professionals. We use this fixed set of numbers to calculate whether your average scores fall in the top 25% (upper quartile) middle 50% (median) or bottom 25% (lower quartile) of the benchmarks we currently hold in our database.
Here’s the spiel from our MSF Report:
“Benchmarks provided are based on data collected from a volunteer sample of doctors working in a variety of clinical settings from the first phase GMC pilot study in 2006 and from the second phase in September 2008 to July 2009. It should be noted that volunteer samples often perform better than an ‘average’ sample which could make the benchmarks provided artificially high and they may not be representative of your clinical setting.”
When SARD was a baby, we didn’t have any data of our own to play with, so this GMC recommended benchmarking was our best bet. However, now we have 183,300 patient feedback questionnaires held in our database, so we have been working on creating personalised benchmarking data for each trust.
This will certainly affect doctors who work in a mental health setting very favourably, as well as anaesthetists or pathologists, all of whom have a slightly different method of collating patient feedback. For these trusts/specialities we will have created their own separate benchmarks, using all mental health data across SARD, all anaesthetist data, etc. I was running some tests last week and the difference inspired me to write this blog!
Here is the current MSF report for a mental health doctor on SARD:
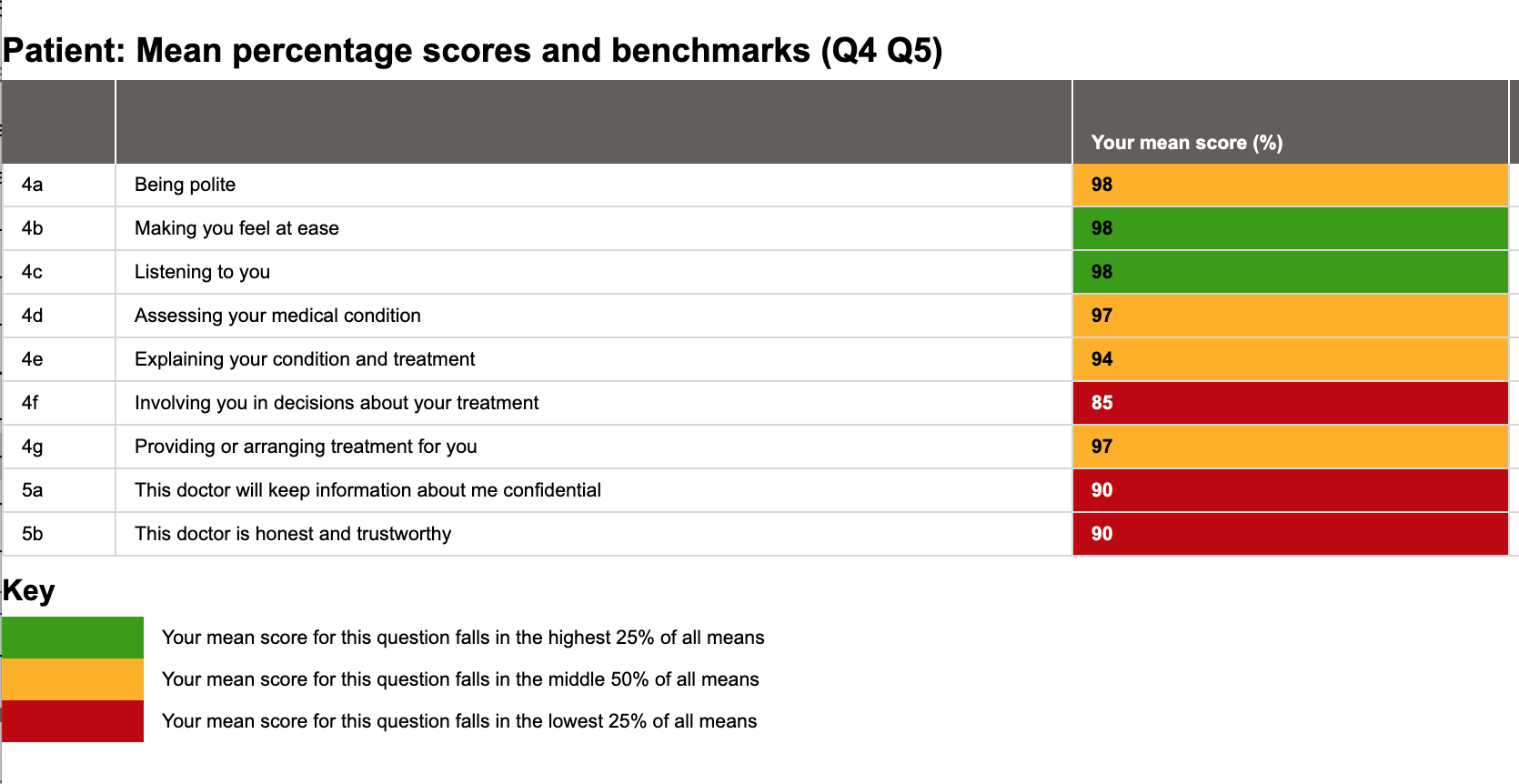
Looks a bit grim. It shouldn’t do, I hear you cry, those scores are mostly in the 90s! But apart from two questions, they are in the median or lower quartile based on our current benchmarking. So, while the scores themselves aren’t bad, there could potentially be improvement in some areas. Except the benchmarking is irrelevant to mental health trusts.
Let’s see the report with our new colour scheme, deployed only a few days ago:
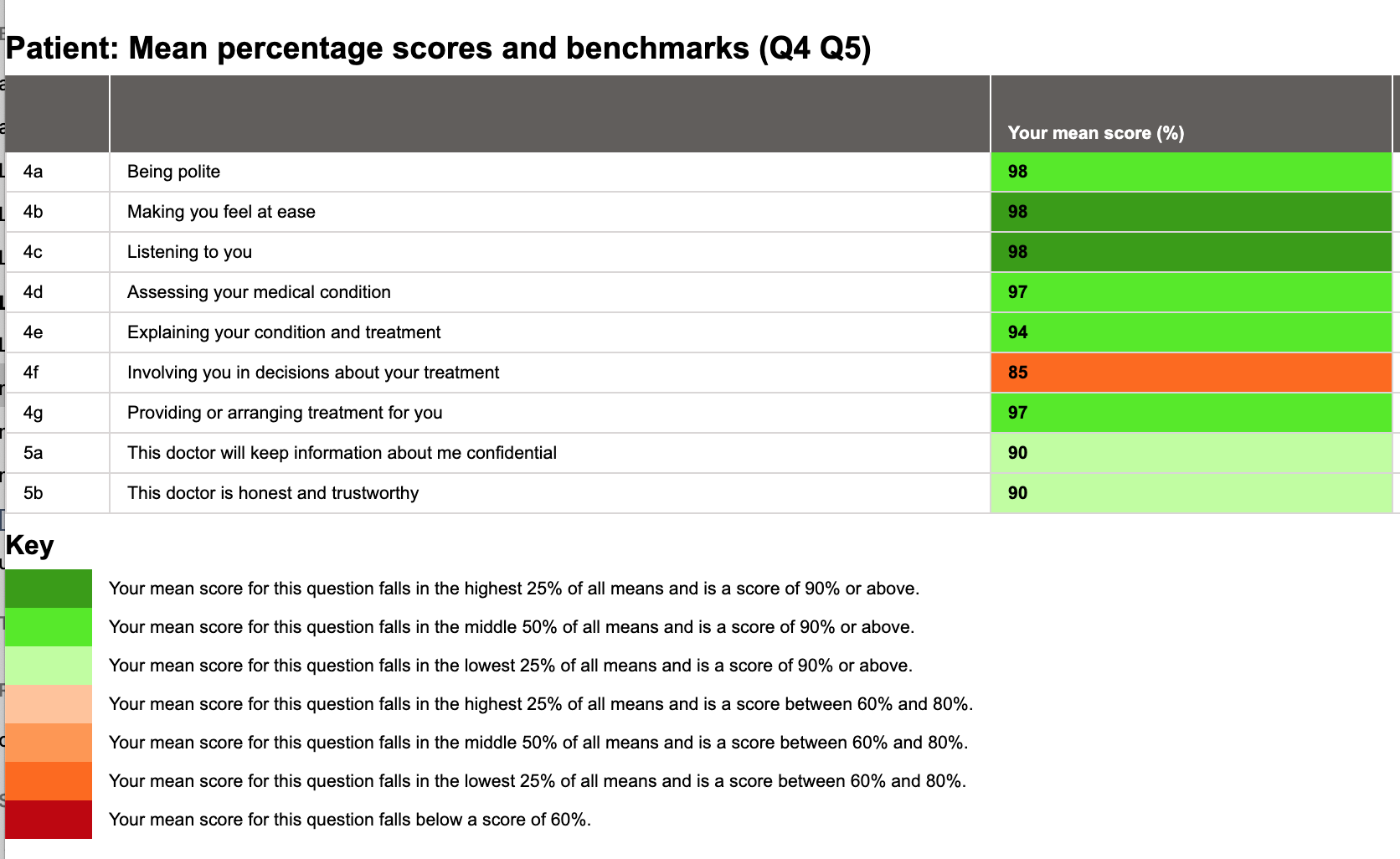
Nice! We’re mostly green! Let’s get some recognition for the fact that the averages scores are all but one in the 90s! The mean score for Question 4f is still within the lower quartile but instead of looking grim it now helpfully points out a singular section we could be improving, as opposed to looking dismal from all angles. We have a couple of lower quartiles for Question 5, but the scores are good in themselves. Now we can see a clear distinction between good scores and good placement amongst a range of scores.
Now let’s do something really exciting. Here is the report again but benchmarked using data across the 10,062 patient feedback questionnaires we have on SARD for mental health doctors.
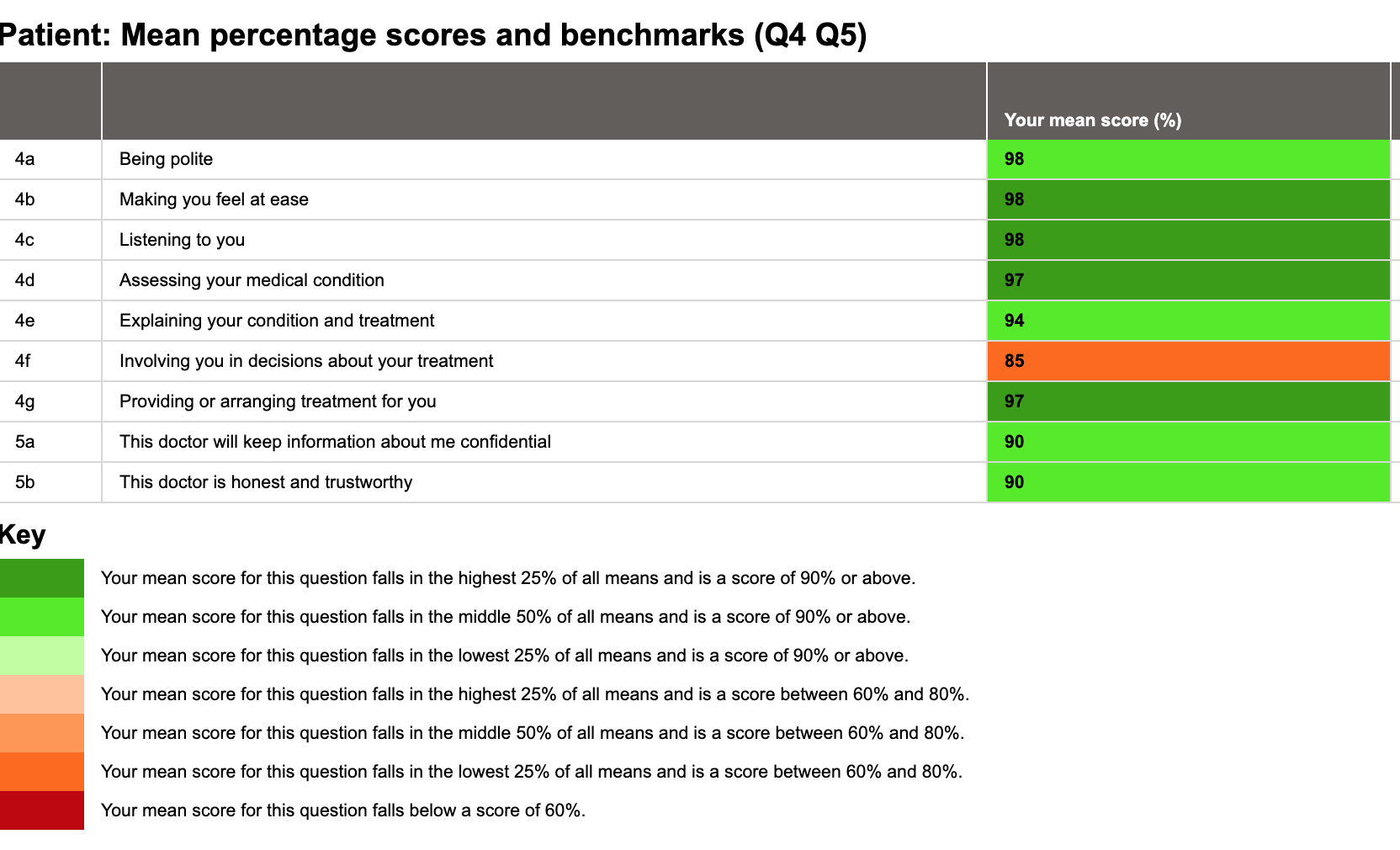
Now that is encouraging. It is a very strong report – high scores, and all but one of those scores are in good standing with this medic’s peers. This is a useful indication of an area needed for improvement – which is positive and constructive feedback. Just look at the difference:
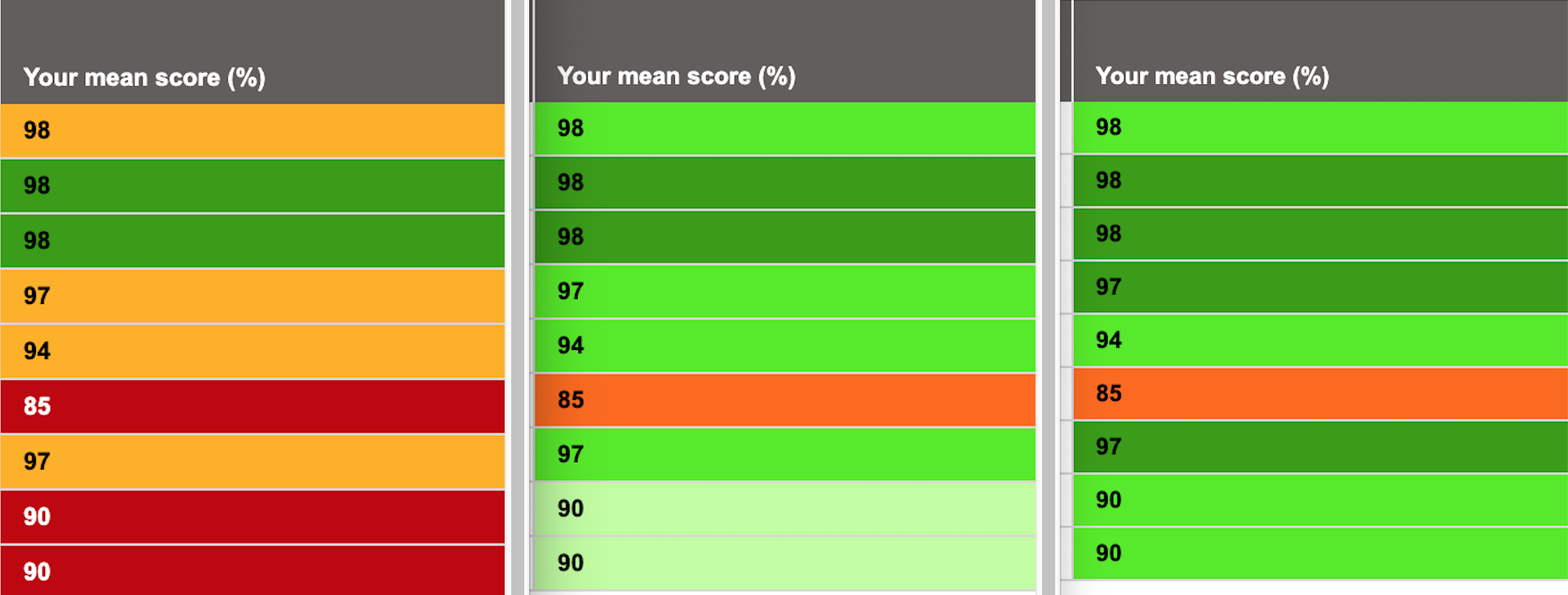
This doctor can take this report to their appraisal and discuss steps for improvement for their own personal development. A score of 85 is not a poor score, but being able to pick it out amongst a sea of great scores is key. There are colleagues who may score highly here and lower elsewhere, so this also encourages peer reviews and sharing good practice. All excellent things.
So we’ve made great progress with 2 of our 3 main features. Currently the RCoA patient feedback form is being typed up and tested. The problem with new form is that immediately we have no benchmarking! But after a year or so we may be in a better position to provide data.
And as for other smaller improvements, we have seen the wonderful Action Needed page receive a huge revamp, fixed little bugs to do with nominating colleagues, and now we are looking at adding useful charts and graphs to help with MSF analysis.
The Future
The next step, which is one of the biggest and scariest, is the implementation and release. When does new benchmarking start? Should it only be available for MSFs created from a moment in time onwards, or will medics want their reports reanalysed? Imagine the work suddenly created!
Just bear with us while we iron out these details to make it as smooth as possible for you. In the meantime you may see little improvements and adjustments rolling out to whet your appetite. Rest assured, new MSF is coming, and it is exciting.











